Expressive Personalized 3D Face Models from 3D Face Scans
PhD project of Stella and ongoing research.
In 2012 I started my PhD project initially on Talking Heads. The idea was to generate a 3D facial animation of a person with accompanying speech given text.
Eventually, I reached an intermediate step with a textured coarse 3D model, as seen below on the left.
The core of my final PhD project was a Higher-Order Singular Value Decomposition (HO-SVD) of a data tensor holding 3D face point clouds. Those were a result of 3D point correspondence estimation. For some databases a temporal alignment was necessary.
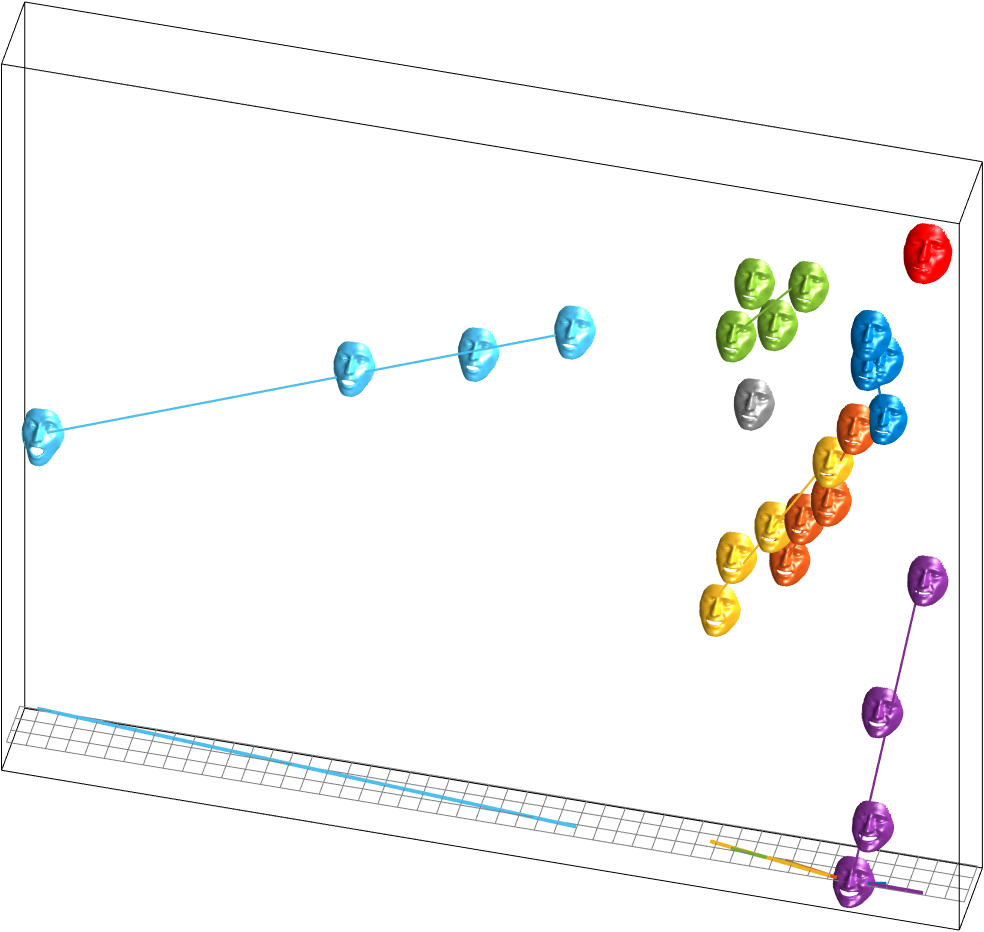
This process unveiled an underlying expression subspace shown in the middle below.
Using the decomposition and carefully designed constraints, we were able to make meaningful edits to the 3D face shapes as shown on the bottom right animation.
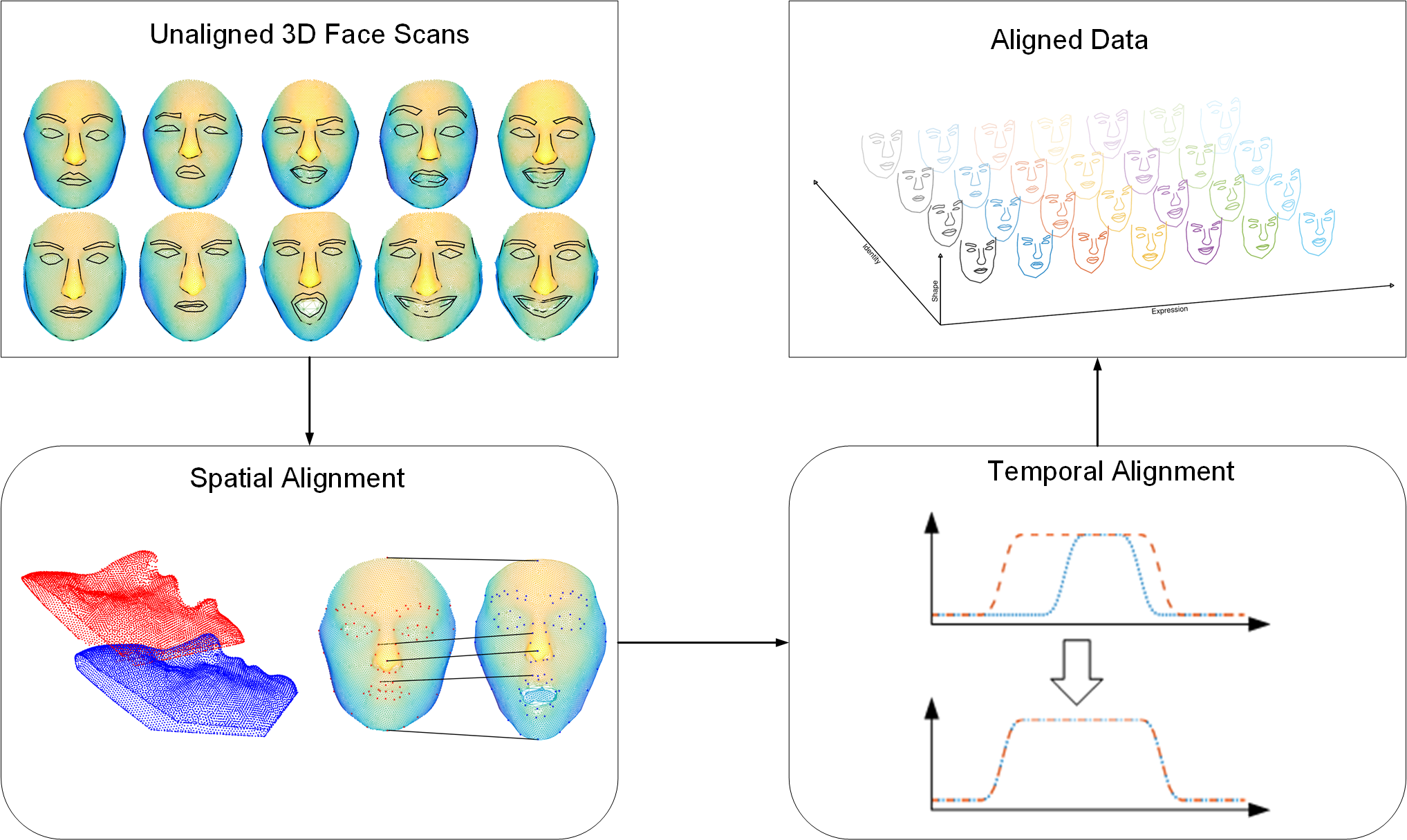
From Data to Aligned Data for Facial Models
Please find an overview of the whole process from 3D face scans to the 3D aligned faces in the following illustration:
Spatial Alignment
Multiple 3D face scans commonly differ in the number of points, and therefore need a general rigid alignment, followed by a registration and correspondence estimation procedure.
In this domain prior knowledge in terms of facial landmarks is employed to improve the results.
Temporal Alignment
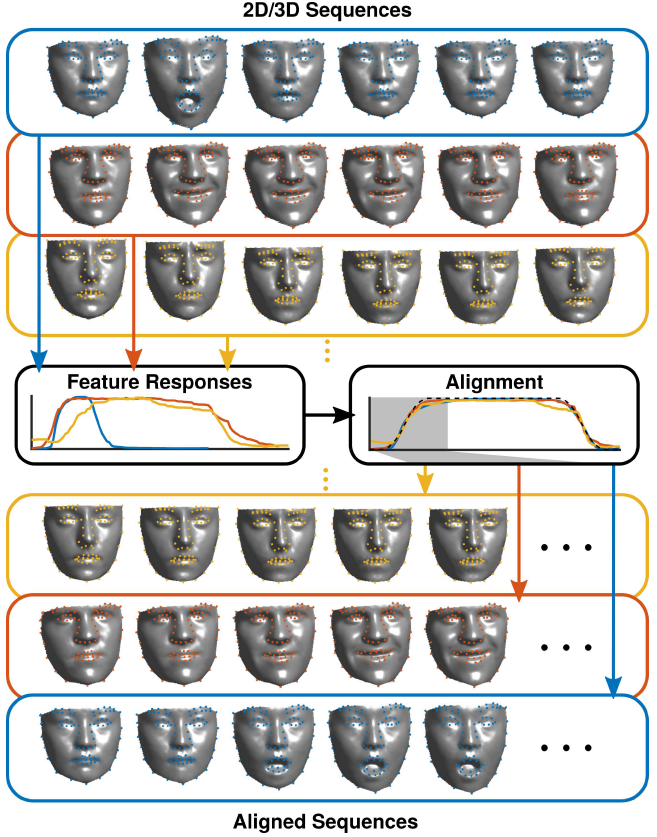
When recording facial motion in 3D, the resulting 3D face scans might differ in their sequence length, hence requiring a temporal alignment.
To achieve this in this project prior knowledge can be employed which is that the facial motion in the recorded sequences follows a common patter, which consists of an increase followed by an decrease of a depicted facial expression forming an emotion.
Hence, an approach was formulated to estimate the expression intensity for each frame. In the following the resulting 1D signals encoding the intensity of facial expression per frame are used to compute an alignment of the 3D face scans, as illustrated.
The 3D Face Model
After all the preprocessing and alignment, a balanced dataset with the same number of 3D points and number of frames has been obtained. This data can now be sorted into a matrix or data tensor and a factorisation method can be employed.
In this work, the Higher-Order Singular Value Decomposition (HO-SVD) was employed to factorize the data tensor into different subspaces. Depending on the chosen order and dimension of the data tensor, new insights were gained.
One of the main contributions was what we referred to as the expression subspace, which revealed a structure in a lower dimensional space.
References
2021
Multilinear Modelling of Faces and Expressions
Stella
Graßhof, Hanno
Ackermann
, Sami Sebastian
Brandt
, and
1 more author
IEEE Transactions on Pattern Analysis and Machine Intelligence, Oct 2021
In this work, we present a new versatile 3D multilinear statistical face model, based on a tensor factorisation of 3D face scans, that decomposes the shapes into person and expression subspaces. Investigation of the expression subspace reveals an inherent low-dimensional substructure, and further, a star-shaped structure. This is due to two novel findings. (1) Increasing the strength of one emotion approximately forms a linear trajectory in the subspace. (2) All these trajectories intersect at a single point – not at the neutral expression as assumed by almost all prior works—but at an apathetic expression. We utilise these structural findings by reparameterising the expression subspace by the fourth-order moment tensor centred at the point of apathy. We propose a 3D face reconstruction method from single or multiple 2D projections by assuming an uncalibrated projective camera model. The non-linearity caused by the perspective projection can be neatly included into the model. The proposed algorithm separates person and expression subspaces convincingly, and enables flexible, natural modelling of expressions for a wide variety of human faces. Applying the method on independent faces showed that morphing between different persons and expressions can be performed without strong deformations.
2019
Expressive Personalized 3D Face Models from 3D Face Scans
In this work, different methods are presented to create 3D face models from databases of 3D face scans. The challenge in this endeavour is to balance the limited training data with the high demands of various applications. The 3D scans stem from various persons showing different expressions, with varying number of points per 3D scan […]
2019
Uncalibrated Non-Rigid Factorisation by Independent Subspace Analysis
Sami Sebastian
Brandt
, Hanno
Ackermann
, and Stella
Graßhof
In 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW) , Oct 2019
We propose a general, prior-free approach for the uncalibrated non-rigid structure-from-motion problem for modelling and analysis of non-rigid objects such as human faces. We recover the non-rigid affine structure and motion from 2D point correspondences by assuming that (1) the non-rigid shapes are generated by a linear combination of rigid 3D basis shapes, (2) that the non-rigid shapes are affine in nature, i.e., they can be modelled as deviations from the mean, rigid shape, (3) and that the basis shapes are statistically independent. In contrast to the majority of existing works, no statistical prior is assumed for the structure and motion apart from the assumption that underlying basis shapes are statistically independent. The independent 3D shape bases are recovered by independent subspace analysis (ISA). Likewise, in contrast to the most previous approaches, no calibration information is assumed for affine cameras; the reconstruction is solved up to a global affine ambiguity that makes our approach simple and efficient. In the experiments, we evaluated the method with several standard data sets including a real face expression data set of 7200 faces with 2D point correspondences and unknown 3D structure and motion for which we obtained promising results.
2018
Unsupervised Features for Facial Expression Intensity Estimation Over Time
M.
Awiszus
, S.
Graßhof
, F.
Kuhnke
, and
1 more author
In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) , Jun 2018
The diversity of facial shapes and motions among persons is one of the greatest challenges for automatic analysis of facial expressions. In this paper, we propose a feature describing expression intensity over time, while being invariant to person and the type of performed expression. Our feature is a weighted combination of the dynamics of multiple points adapted to the overall expression trajectory. We evaluate our method on several tasks all related to temporal analysis of facial expression. The proposed feature is compared to a state-of-the-art method for expression intensity estimation, which it outperforms. We use our proposed feature to temporally align multiple sequences of recorded 3D facial expressions. Furthermore, we show how our feature can be used to reveal person-specific differences in performances of facial expressions. Additionally, we apply our feature to identify the local changes in face video sequences based on action unit labels. For all the experiments our feature proves to be robust against noise and outliers, making it applicable to a variety of applications for analysis of facial movements.
2017
Projective structure from facial motion
Stella
Graßhof, Hanno
Ackermann
, Felix
Kuhnke
, and
2 more authors
In 2017 Fifteenth IAPR International Conference on Machine Vision Applications (MVA) , May 2017
Nonrigid Structure-From-Motion is a well-known approach to estimate time-varying 3D structures from 2D input image sequences. For challenging problems such as the reconstruction of human faces, state-of-the-art approaches estimate statistical shape spaces from training data. It is common practice to use orthographic or weak-perspective camera models to map 3D to 2D points. We propose to use a projective camera model combined with a multilinear tensor-based face model, enabling approximation of a dense 3D face surface by sparse 2D landmarks. Using a projective camera is beneficial, as it is able to handle perspective projections and particular camera motions which are critical for affine models. We show how the nonlinearity of the projective model can be linearized so that its parameters can be estimated by an alternating-least-squares approach. This enables simple and fast estimation of the model parameters. The effectiveness of the proposed algorithm is demonstrated using challenging real image data.
2017
Apathy Is the Root of All Expressions
Stella
Graßhof, Hanno
Ackermann
, Sami S.
Brandt
, and
1 more author
In 2017 12th IEEE International Conference on Automatic Face Gesture Recognition (FG 2017) , May 2017
In this paper, we present a new statistical model for human faces. Our approach is built upon a tensor factorisation model that allows controlled estimation, morphing and transfer of new facial shapes and expressions. We propose a direct parametrisation and regularisation for person and expression related terms so that the training database is well utilised. In contrast to existing works we are the first to reveal that the expression subspace is star shaped. This stems from the fact that increasing the strength of an expression approximately forms a linear trajectory in the expression subspace, and all these linear trajectories intersect in a single point which corresponds to the point of no expression or the point of apathy. After centring our analysis to this point, we then demonstrate how the dimensionality of the expression subspace can be further reduced by projection pursuit with the help of the fourth-order moment tensor. The results show that our method is able to achieve convincing separation of the person specific and expression subspaces as well as flexible, natural modelling of facial expressions for wide variety of human faces. By the proposed approach, one can morph between different persons and different expressions even if they do not exist in the database. In contrast to the state-of-the-art, the morphing works without causing strong deformations. In the application of expression classification, the results are also better.
2015
Estimation of face parameters using correlation analysis and a topology preserving prior
Stella
Graßhof, Hanno
Ackermann
, and Jörn
Ostermann
In 2015 14th IAPR International Conference on Machine Vision Applications (MVA) , May 2015
Candide-3 is a well-known model, used to represent triangular meshes of human faces. It is common to only estimate 17 to 21 of the 79 model parameters. We show that these are insufficient to fit model vertices to facial feature points with low error and if more parameters are estimated, the model mesh deforms to unnatural configurations. To overcome this problem, we propose a novel solution: Given facial feature points, we propose to estimate the model parameters in subsets in which they are uncorrelated. Additionally we present a term to penalize topologically incorrect triangular mesh configurations. As a result the average mean squared error between facial feature points and model vertices is reduced by 90%, while face topology is preserved.
2013
Performance of Image Registration and Its Extensions for Interpolation of Facial Motion
Stella
Graßhof, and J.
Ostermann
In Pacific-Rim Symposium on Image and Video Technology (PSIVT) Workshops , 2013
We compare the performance of an intensity based nonparametric image registration algorithm and extensions applied to frame interpolation of mouth images. The mouth exhibits large deformations due to different shapes, additionally some facial features occlude others, e.g. the lips cover the teeth. The closures and disclosures represent a challenging problem, which cannot be solved by the traditional image registration algorithms.
The tested extensions include local regularizer weight adaptation, incorporation of landmarks, self-occlusion handling and penalization of folds, which have all been examined with different weight parameters.
Since the performance of these algorithms and extensions turns out to be superior in case of mouth closures, we provide an algorithm for the automatic selection of deformable template and static reference image for the registration procedure. Subjective tests show that the quality of results for interpolation of mouth images is enhanced by this proposal.